Adaptive Selection of Local and Non-local Attention Mechanisms for Speech Enhancement
In speech enhancement tasks, local and non-local attention mechanisms have been significantly improved and well studied. However, a natural speech signal contains many dynamic and fast-changing acoustic features, and focusing on one type of attention mechanism (local or non-local) is unable to precisely capture most discriminative information for estimating target speech from background interference. To address this issue, we introduce an adaptive selection network to dynamically select an appropriate route that determines whether to use the attention mechanisms and which attention mechanism to use for the task. We train the adaptive selection network using reinforcement learning with a developed difficulty-adjusted reward that is related to the performance, complexity, and difficulty of target speech estimation from the noisy mixtures. Consequently, we propose an Attention Selection Speech Enhancement Network (ASSENet), which consists of an adaptive selection network and a local and non-local attention based speech enhancement network. In particular, the ASSENet incorporates both local and non-local attention and develops the attention mechanism selection technique to explore the appropriate route of local and non-local attention mechanisms for speech enhancement tasks. The results show that our method achieves comparable and superior performance to existing approaches with less computational cost.
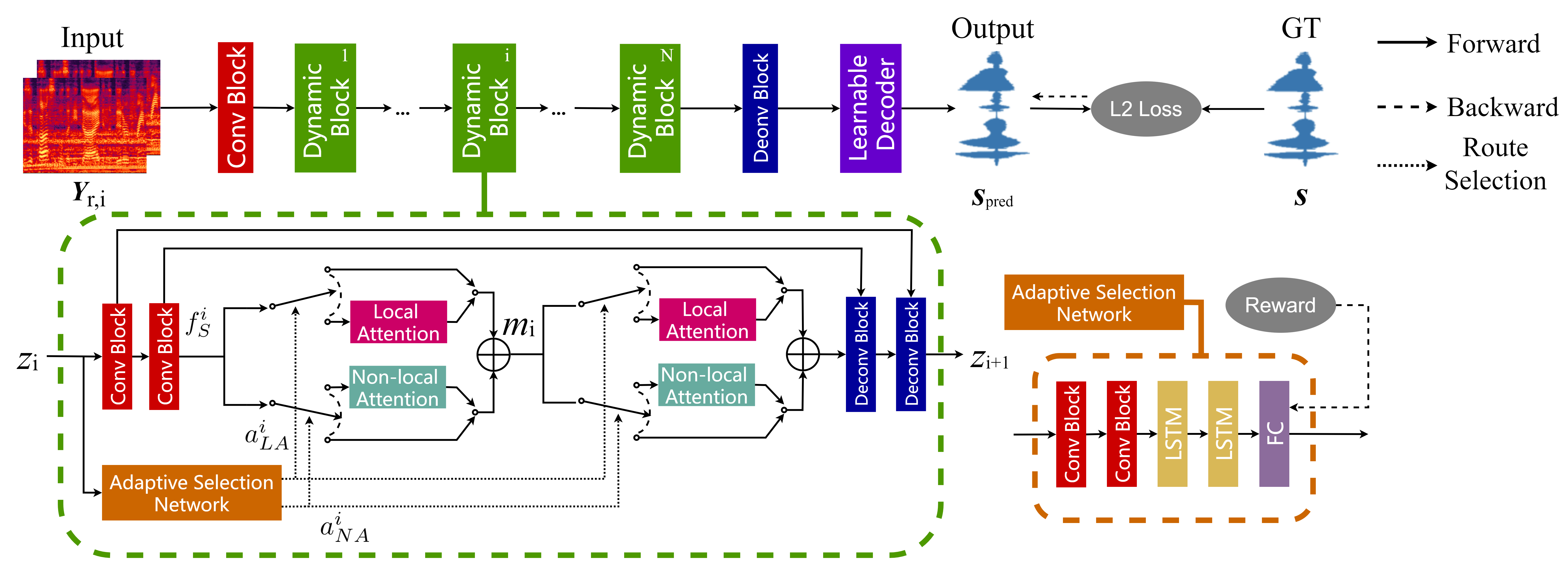
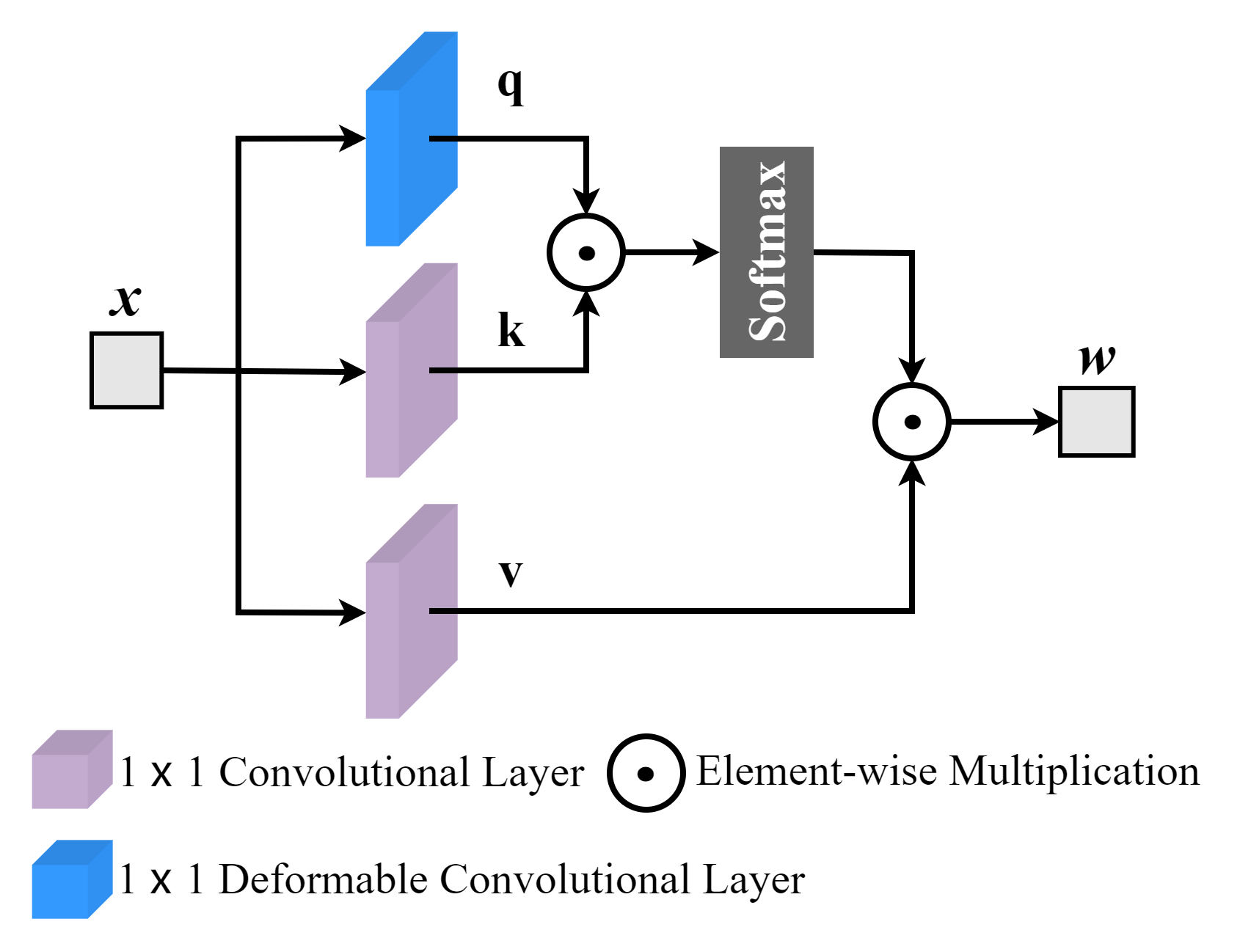
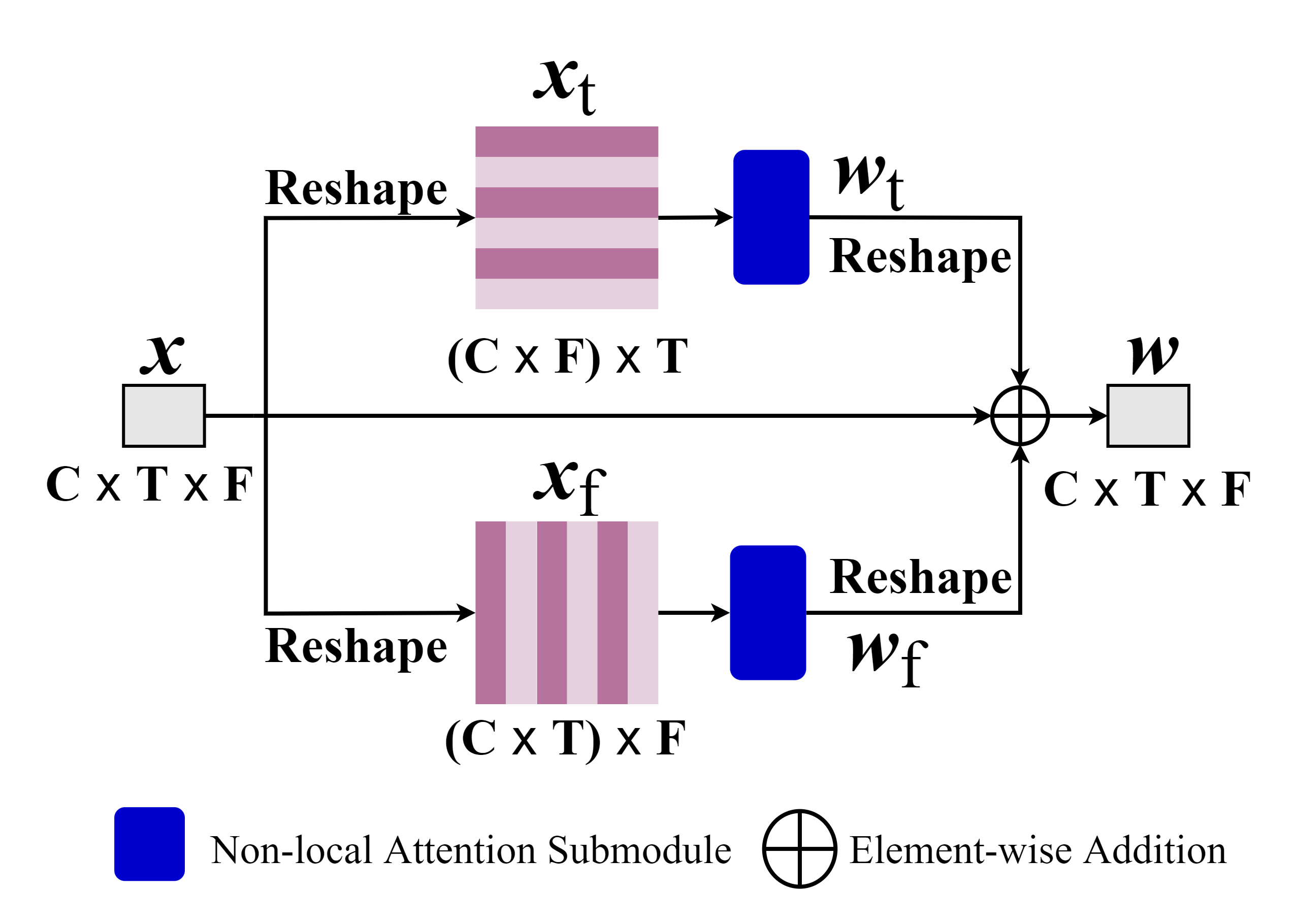
The demo of ASSENet
Task and dataset- We evaluated the proposed ASSENet on Single-channel Speech Enhancement task.
- We use WSJ0-SI 84 + DNS Challenge dataset to train the ASSENet. We randomly select 12 male speakers and 12 female speakers from totally 83 speakers (42 males and 41 females), and each speaker pronounced around 400 sentences. Finally, the clean data contained 9600 utterances in total (4800 male utterances and 4800 female utterances). Next, we mix 9600 utterances with noise in -5, -4, -3, -2, -1, 0 dB SNR levels.
Demos on Real-world data
| Original | ASSENet Enhanced | |
|---|---|---|
| Sample 1 | ||
| Sample 2 | ||
| Sample 3 |
NOTE:
- "Adaptive Selection of Local and Non-local Attention Mechanisms for Speech Enhancement", submitted to Neural Networks
- The code will be released in the near future